
What is RAG?
Retrieval Augmented Generation architectures and use cases

Today I want to talk about a core part of any LLM based application that is not just a wrapper around openAI API.
Retrieval augmented generation (RAG) is a technique to combine information retrieval with an LLM. It allows the foundational model to use a set of documents as a knowledge base.
Think about how we use Notion or Obsidian as a second brain. It's a good analogy for RAG. It lets our model be up-to-date with the latest knowledge and reduces hallucinations
(Cheap) Superpowers for your LLM
RAG often solves the some pain points that make building LLMs application hard:
Reduced hallucination by providing context to your model
Easy updates: It allows using recent data without long and expensive fine-tuning cycles
Factual transparency: your model can accurately reference relevant documents
Now that we have seen an overview of use cases, let's see what is RAG and how it works.
What is RAG?
The idea behind RAG is very simple: whenever we prompt the LLM, we look at set of documents (knowledge base) and find the items most similar to our query. Then we pass the prompt and the context to the model.
On a high level, the RAG architecture uses is based on 3 things:
Language model
Knowledge base
Similarity measure
Popular RAG architectures
Let's see what are the 3 most popular architectures for Retrieval-Augmented generation systems.
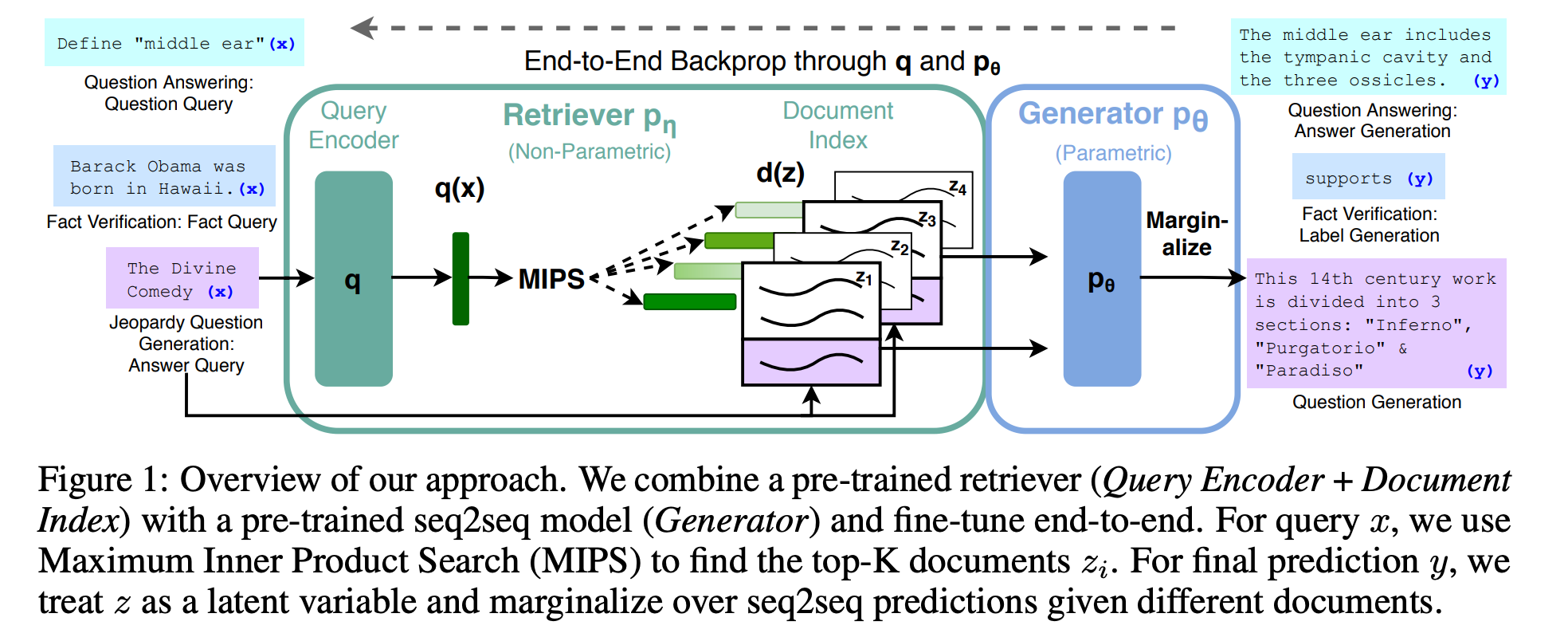
Basic RAG: this architecture was introduced in the paper Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. It combines a retrieval componenet with a sequence to sequence model.
How it works:
The input query is encoded and used to retrieve relevant documents from an index
The selected documents are concatenated to the input query
The query + documents are fed to a language model, which generates the output
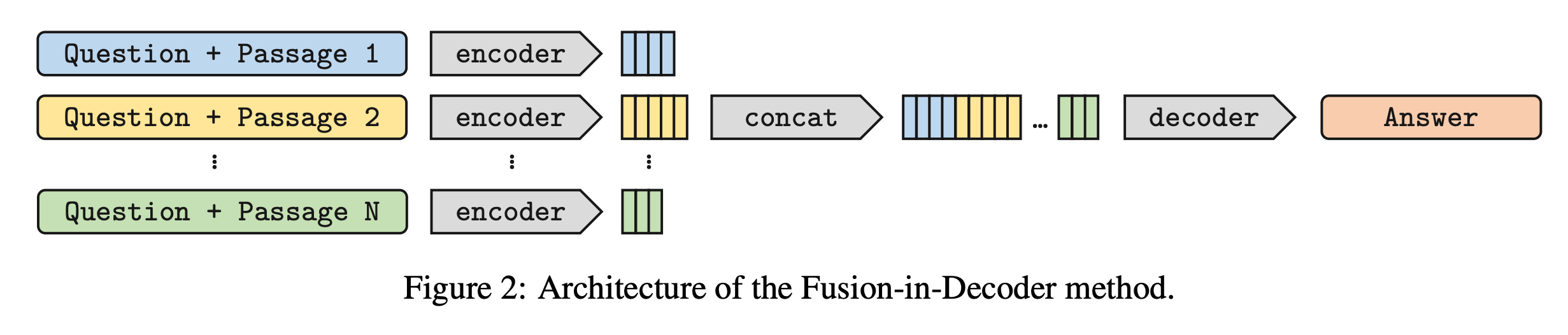
Fusion-in-Decoder: this approach comes from the paper Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering, and it extends the Basic RAG strategy. How it works:
(same as Basic RAG) The input query is encoded and used to retrieve relevant documents from an index
Each retrieved document is processed separately by an encoder
Attention is used on encoded queries + documents simultaneously
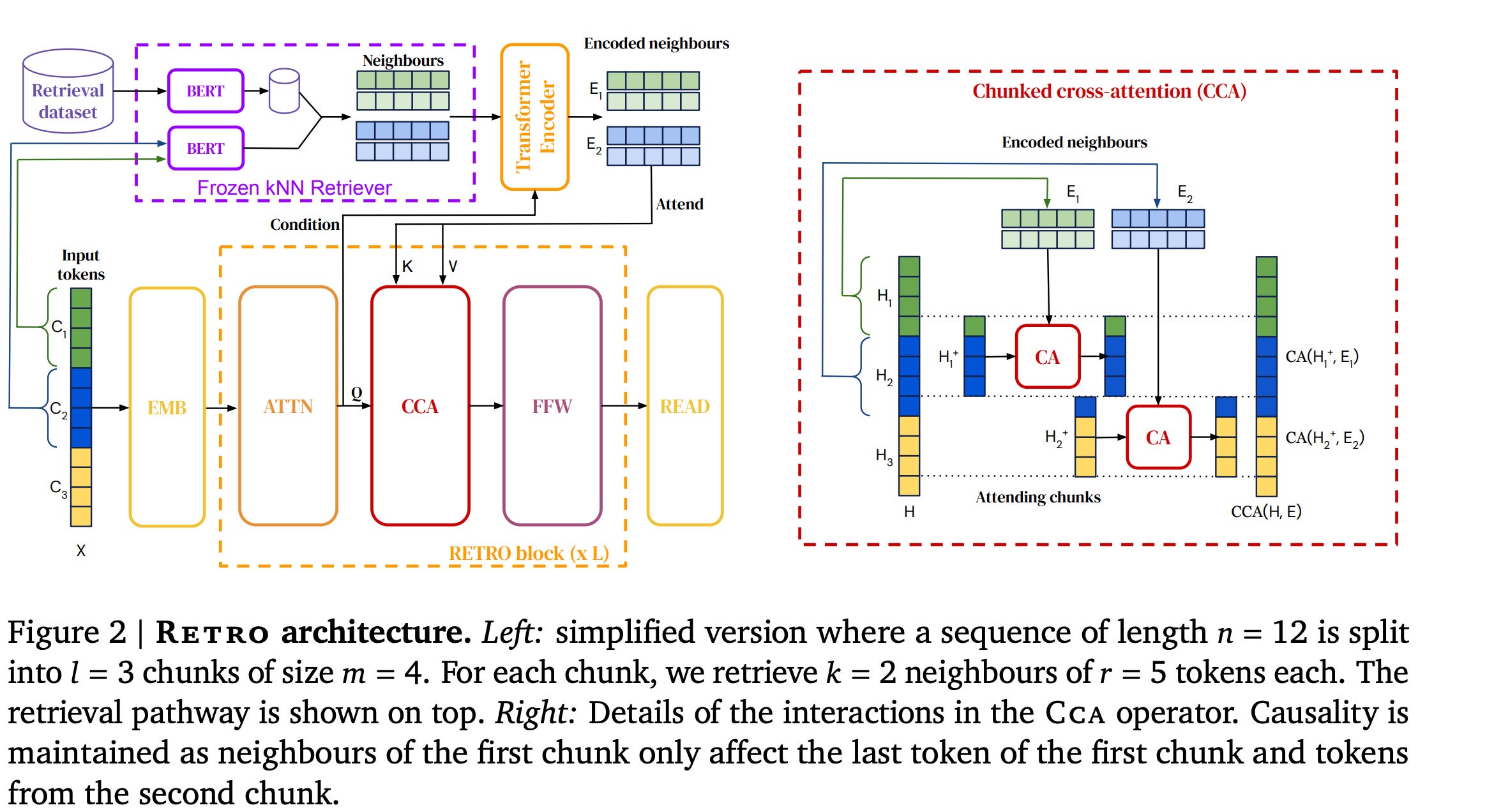
Retrieval-Enhanced Transformer: from the paper Improving language models by retrieving from trillions of tokens. This approach incorporates the retrieval into the transformer architecture.
How it works:
At each layer of the Transformer, retrieval is performed based on the current hidden states
The retrieved information is then incorporated into the next layer
Choosing a system
Each RAG system has pros and cons, and may be more suitable for different tasks or constraints.

Keeping this in mind, there isn't a one-size-fit-all RAG system, as each has its own tradeoffs. The best RAG architecture to use is the one that best aligns with your functional and non functional requirements.